- 1
- We have a collection where every item has a different type
- 2
-
The
item*2operation does something different on each loop! Python has to check the type ofitemEVERY. SINGLE. TIME. This really slows things down.
2
2.0
11
oneone
2
(2+0j)
Although it might not always seem like it, Python is actually very easy to use (compared to other languages). Not only does it have a very readable syntax, but it also let’s us mix-and-match types with impunity. Python deals with the operations on different types “on-the-fly”. Consider the following case:
item*2 operation does something different on each loop! Python has to check the type of item EVERY. SINGLE. TIME. This really slows things down.
2
2.0
11
oneone
2
(2+0j)The slow-down incurred by having to check the type of each variable before doing an operation is quite problematic in numerical computing, which usually means dealing with large amounts of data, like millions or billions of values. Looping through such large amount of data (i.e. vectors, arrays, and matrices) the basis for all numerical computations.
Example 8.1 (Invert an image) Given a greyscale image below, invert the colors so that dark becomes light, and vice-versa.

Solution
Images are represented as 2D matrices with values between 0 and N indicating the color, where N=255 in this case. We can look at a small piece of the array to confirm:
imread function fetches the image file and returns it as a numpy array, which we’ll learn about below.
[[198 198 198 199 199 199 199 199 197 198]
[198 198 198 199 199 199 199 199 197 198]
[198 198 198 199 199 199 199 199 198 198]
[198 198 198 199 199 199 199 199 198 198]
[198 198 198 199 199 199 199 199 198 198]
[198 198 198 199 199 199 199 199 198 199]
[198 198 198 199 199 199 199 199 198 199]
[198 198 198 199 199 199 199 199 198 199]
[199 199 199 199 198 198 198 198 197 198]
[199 199 199 199 198 198 198 198 198 199]]To invert the greyscale values in im using traditional for-loops, we need to do 2 nested loops to scan along each row. Just for fun, let’s also record the time it takes to do this:
from time import time
tstart = time()
im2 = im.copy()
im_max = im.max()
for i in range(im.shape[0]):
for j in range(im.shape[1]):
im2[i, j] = im_max - im[i, j]
tfinal = time() - tstart
print(f"This took {tfinal} seconds")This took 0.03530001640319824 secondsNow we can visualize the images side-by-side to confirm we achieved our objective:
fig, ax = plt.subplots(2, 1)
ax[0].imshow(im, cmap=plt.cm.bone)
ax[1].imshow(im2, cmap=plt.cm.bone)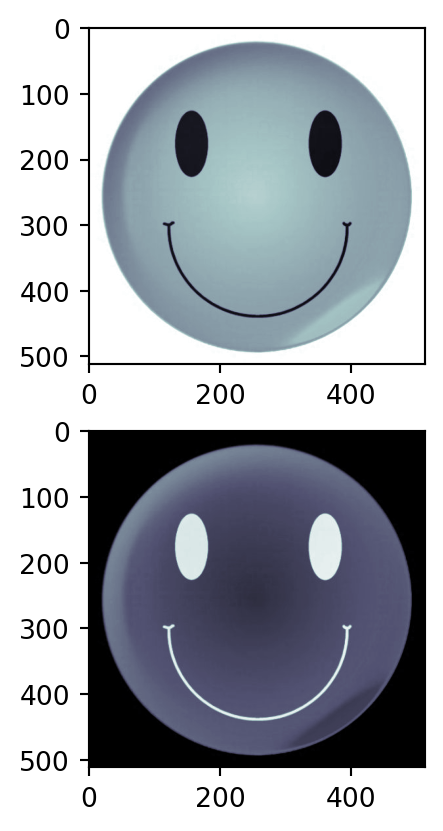
Comments
Note that indexing into this 2D numpy array is different than a 2D list.
arr[0][0]…we index into the “outer” list to get access to the “inner” list, so it’s like chaining the indices.numpy array we use arr[0, 0]. We access all the dimensions at the same time.ndarraynumpy is not included in Python. We need to install it separately. If we used Anaconda to get ourselves started, then we get numpy included (along with a few hundred other packages). So despite the fact that numpy is pretty much mandatory for any numerical computing, it is still a separate package with its own “interface” that we must learn.
The main feature of numpy is that is provides a new data-type known as an ndarray, or “ND-array” meaning “N-Dimensional Array”. This array looks and acts a lot like a list but has one key difference:
Every item in an
ndarraymust be the same type!
This means that is is now possible to scan an ndarray without checking the type of each item, thus avoiding that slow process.
HOWEVER, it is not quite that simple. If we attempt to use Python for-loops to index into ndarrays Python will still check the type. However, numpy provides us with literally hundreds of functions that we can use to accomplish almost anything that would otherwise require for-loops.
The downside is that using numpy is like learning a language within a language.
Probably 99% of the time we can get by using some combination of numpy functions and functionality, but if we are doing something really special the use of a for-loop may be necessary. In this case we can still avoid slow Python for-loops by using a package called numba. numba lets us write functions with for-loops to scan through ndarrays, but the loops are fast. This package basically provides a way to write a for-loop with avoids the type-checking of each item. It’s a bit of a pain to use though.
It uses a technique called “just in time” compilation, and it looks at the type of input data to the function, then compiles a version of the function that works on that data type only. This is another way to avoid type checking since it knows that the data received by the function is of one single type.
Since each element in an ndarray is of the same type, then we shouldn’t be surprized that the ndarray itself has a type, and that type corresponds to the type of the array’s contents.
ndarray, we can optionally specify dtype, in this case int. dtype stands for “data type” and it limits which type of values can be stored within arr. The default is float.
ndarray, which is it.
ndarray itself has an “attribute” which tells us the type of the data inside arr. numpy gives us a bit more information that just int…it says int64 which means an integer represented using 64-bits, so we can count to very high values.
<class 'numpy.ndarray'>
int64We can create arrays with all the usual types:
arr2 = np.array([1, 2, 3], dtype=float)
print(arr2)
arr3 = np.array([0, 1, 0], dtype=bool)
print(arr3)
arr4 = np.array([1, 2, 3], dtype=complex)
print(arr4)[1. 2. 3.]
[False True False]
[1.+0.j 2.+0.j 3.+0.j]Counting in binary is just like using familiar decimal numbers, but there are only 2 symbols (0 and 1) instead of 10 (0, 1, 2, 3, etc). This means we run out of symbols more often, so need to increment the placeholder more often. For example:
| Decimal | Binary |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 10 |
| 3 | 11 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
| 8 | 1000 |
Bits represent 0’s and 1’s, so the more bits we use, the larger the number we can store.
14,013,403 vs 1.4013403 each have 8 digits. Adding more digits lets us either count higher or have more precision, depending on whether the number is an int or a float.WHy not just use the maximum number of bits? Using less bits means:
Numpy lets us control the number of bits used to store data if we wish. For example we can do the following to confirm that they do take up different amounts space:
import numpy as np
arr2 = np.array([1, 2, 3], dtype=np.int8)
print(arr2.nbytes)
arr3 = np.array([1, 2, 3], dtype=np.int16)
print(arr3.nbytes)
arr4 = np.array([1, 2, 3], dtype=np.float64)
print(arr4.nbytes)3
6
24It is easy to convert between types using the astype() method attached to each ndarray:
arr = np.array([1, 2, 3])
arr = arr.astype(int)
print(arr)[1 2 3]One of the ways that numpy let’s us avoid the use of for-loops is by changing they way mathematical operations like + and * work.
Recall that for lists, multiplication by 2 doubled the length of the list:
arr = [1, 2, 3] * 2
print(arr)[1, 2, 3, 1, 2, 3]With numpy, multiplication does actual math!:
import numpy as np
arr = np.array([1, 2, 3]) * 2
print(arr)[2 4 6]This is called “elementwise” operation because it operates on each element, rather than on the whole array.
numpy also allows for elementwise operations between 2 arrays:
arr1 = np.array([1, 2, 3])
arr2 = np.array([10, 20, 30])
print(arr1/arr2)[0.1 0.1 0.1]Note that that arr1 and arr2 must be the same size for this to work. If they are not the same size Numpy will attempt something called “broadcasting” which we’ll discuss later.
All mathematical operations are supported:
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
print( arr1 + arr2)
print( arr1 - arr2)
print( arr1 * arr2)
print( arr1 / arr2)
print( arr1 // arr2)
print( arr1 % arr2)
print( arr1**arr2)[5 7 9]
[-3 -3 -3]
[ 4 10 18]
[0.25 0.4 0.5 ]
[0 0 0]
[1 2 3]
[ 1 32 729]In all cases, each of the above lines performs the stated operation using element i of arr1 and element i of arr2.
When we perform elementwise operations with ndarrays what actually happens is that “behind the scenes” some special code is run which performs for-loops that do not check the type. In this way we can achieve much faster speeds.
In the above example we used elementwise operations to perform an operation on an image, providing a huge speed-up. The lesson is that we should NOT use for-loops to process the individual elements a big array. However, it is still OK to use a for-loop to process a big batch of images, using numpy functions inside the loop, like this:
ims = [im1, im2, im3, im4, im5]
mx = []
for im in ims:
mx.append(im.max()) The point is that looping over a small number of items and doing big calculations on each loop is fine, common, and usually unavoidable.
When we looked at Python containers like lists and strings, we used the various methods that were attached to them. These methods are just functions which operate on the object, so vals.sort() is the same as sorted(vals).
ndarray also have a lot of methods attached to them, which we’ll cover later. They also have a lot of “attributes” attached to them. Attributes store information about the array, such as size and shape. A list of useful “attributes” on ndarrary is given below:
ndarrays
| Attributes | Description |
|---|---|
ndim |
Number of dimension of the array |
size |
Number of elements in the array |
shape |
The size of the array in each dimension |
dtype |
Data type of elements in the array |
itemsize |
The size (in bytes) of each elements in the array |
data |
The buffer containing actual elements of the array in memory |
T |
View of the transposed array |
dict |
Information about the memory layout of the array |
flat |
A 1-D iterator over the array |
imag |
The imaginary part of the array |
real |
The real part of the array |
nbytes |
Total bytes consumed by the elements of the array |
The shape, size and ndim get used a lot, while the rest are mostly there for debugging.
import numpy as np
arr = np.array([[2, 3, 4], [3, 4, 5]])
print(arr.shape)
print(arr.size)
print(arr.ndim)(2, 3)
6
2Attributes discussed above are values which do not need to be computed, like arr.size. There are many other properties of an array which would like to know, such as the maximum or minimum value within it. This sort of information must be calculated on demand using the methods attached to the ndarrays.
arr = np.array([4, 3, 6])
print(arr.max())
print(arr.min())6
3Note that because these methods require an actual computation on the array, it is best to store their result if it needs to be used many times:
arr = np.array([4, 3, 6])
amax = arr.max()ndarrays which calculate some property based on the array contents
| Method | Description |
|---|---|
max |
Return the maximum along a given axis. |
min |
Return the minimum along a given axis. |
trace |
Returns the sum along diagonals of the array. |
sum |
Return the sum of the array elements over the given axis. |
cumsum |
Returns the cumulative sum of the elements along the given axis. |
mean |
Returns the average of the array elements along given axis. |
var |
Returns the variance of the array elements, along given axis. |
std |
Returns the standard deviation of the array elements along given axis. |
prod |
Returns the product of the array elements over the given axis |
cumprod |
Returns the cumulative product of the elements along the given axis. |
all |
Returns True if all elements evaluate to True. |
any |
Returns True if any of the elements of a evaluate to True. |
By default all of the methods in Table 8.2 operate on all axes. For instance, max returns a single value which is the maximum value for the entire array. Most of these methods also accept an axis argument, in which case a new ndarray is returned which is one dimension smaller than the original array, containing the result obtained by only looking at values along a given axis.
Multidimensional arrays are very common in numerical programming. Some examples are:
[200, 200, 3].
As “simple humans” we can visualize 1D, 2D and 3D images and arrays quite well, but not higher. Figure 8.5 shows this progression. It also includes the definition of array “shape” as well:
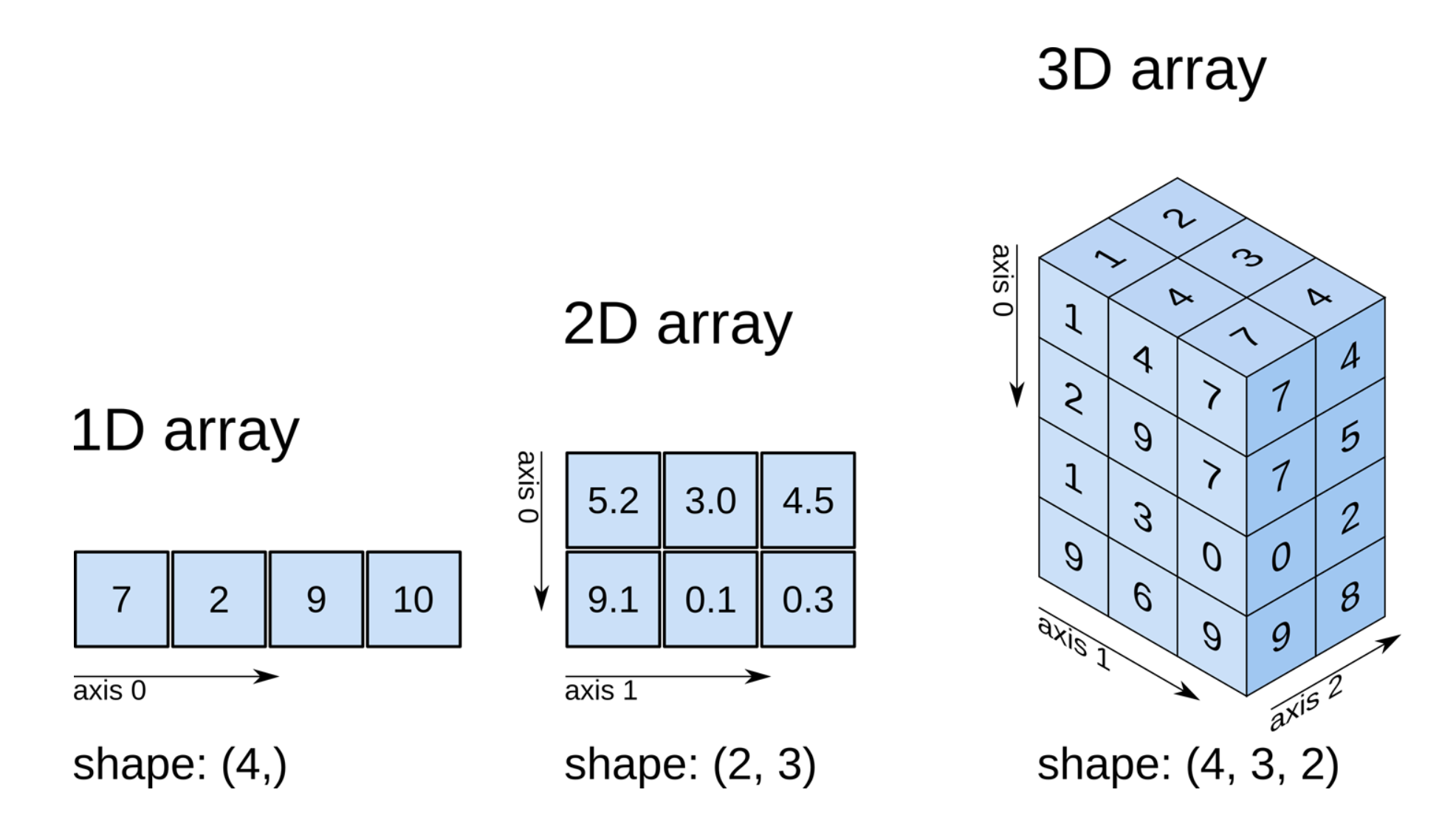
It is actually possible to use the “list of lists” style indexing with ndarrays, as shown below:
import numpy as np
arr = np.random.rand(5, 5)
print(arr[0][0])
print(arr[0, 0])0.6650978092989233
0.6650978092989233But numpy offers several special features which require the [0, 0] style indexing, so it’s necessary to learn this. For instance, we can extract a subsection of an array using:
import numpy as np
arr = np.random.rand(9, 9)
arr2 = arr[:3, :3]
print(arr2)[[0.48514689 0.33382921 0.4300478 ]
[0.92626912 0.0149962 0.85853595]
[0.42822341 0.03526443 0.8251628 ]]ndarraysIndexing an ndarray behaves a bit differently than we have seen with nested lists. Recall that indexing into a nested list (i.e. a “list of lists”) worked as follows:
[0], we retrieve the list stored at location 0.
[0] we index into the list we obtained from the first [0].
[1, 2, 3]
1For an ndarray, the indexing is done within a single pair of brackets:
arr = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
1print(arr[0, 0])row and col simultaneously and receive the value stored at that location.
1Visualizing 4D and higher becomes a challenge. Humans are fundamentally incapable of visualizing higher dimension, so we need some tricks, as illustrated in the following example.
Example 8.5 (Thinking about higher dimensional arrays) Consider the array shown in Figure 8.5. How would you access the value of “31”?
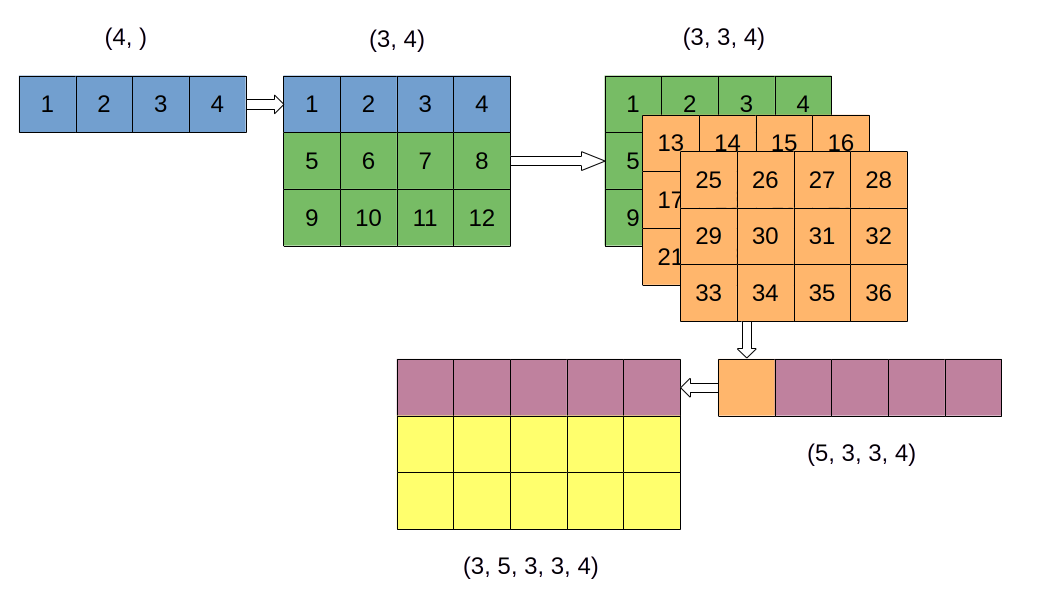
Solution
1 to N+1, where N is the total number of elements in the final array
31Comments
numpy uses “C” ordering, which means that each new axis gets added to the beginning of the of list of axes. In other words, the highest dimension is indexed using the first index, and lowest dimension is last. Technically, this means that indexing is like arr[z, y, x], although it should be stressed that numpy does not name these axes. In fact, numpy calls these axes 0, 1 and 2 which is a bit counter-intuitive.
The alternative to “C” ordering if “F” ordering, referring to FORTRAN, where new dimensions are added to the end of the list of axes.
It is sometimes helpful to think of multidimensional arrays as being reshaped to 1D arrays. In fact, this is how computers “think” about. The values are laid out 1D block in memory. We can change the shape of any array as follows:
arr = np.arange(24)
print(arr)[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]arr = arr.reshape([4, 6])
print(arr)[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]]arr = arr.reshape([2, 12])
print(arr)[[ 0 1 2 3 4 5 6 7 8 9 10 11]
[12 13 14 15 16 17 18 19 20 21 22 23]]We can swap between any shapes as long as the total number of elements is conserved.
We can also retrieve subsections of an array using “slicing” that we discussed in the previous chapter:
arr = np.arange(25)
arr = arr.reshape([5, 5])
print(arr)
print(arr[0:3, 0:3])[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]
[20 21 22 23 24]]
[[ 0 1 2]
[ 5 6 7]
[10 11 12]]We can also write to subsections of an array:
arr = np.arange(25)
arr = arr.reshape([5, 5])
arr[0:3, 0:3] = 0
print(arr)[[ 0 0 0 3 4]
[ 0 0 0 8 9]
[ 0 0 0 13 14]
[15 16 17 18 19]
[20 21 22 23 24]]The defaults also apply, so we can omit some values:
arr = np.arange(25)
arr = arr.reshape([5, 5])
1arr[:3, 3:] = 0
print(arr):3 means the first 3 rows (0, 1 and 2), but does not include row 3.
[[ 0 1 2 0 0]
[ 5 6 7 0 0]
[10 11 12 0 0]
[15 16 17 18 19]
[20 21 22 23 24]]As with mathematical functions, logical comparisons are also done elementwise:
arr are less than 0.5
mask reveals that it contains True and False values, which are the result of the logical comparison.
[[ True True False False False]
[ True True False False True]
[False True True False True]
[False True False True True]
[ True False False True False]]We can use ndarrays filled with boolean values as “masks” to retrieve or write values from the locations where the mask is True.
mask will contain a True value in all locations where arr < 0.1.
arr that were < 0.1 using mask for the index.
[0.06511094 0.01756348]We can also use masks to write values:
import numpy as np
arr = np.random.rand(5, 5)
mask = arr < 0.5
1arr[mask] = 0.0
print(arr)numpy to put the value of 0.0 into arr at all locations where mask is True.
[[0. 0.50419087 0. 0. 0.86408462]
[0. 0. 0. 0.71625372 0.50917495]
[0. 0.74495557 0.59446975 0. 0.84851075]
[0. 0.50375098 0. 0.7122996 0. ]
[0. 0.70607222 0. 0. 0. ]]Fancy indexing works like the masks discussed above for masks, but with actual numerical index values:
[0. 0.42762076 0.61522461 0.44964016 0. 0.
0.02798985 0.20205376 0. 0.63866539]When working with higher-dimensional arrays (2D, 3D, etc), we must specify the index of each axis in its own list (like above for 1D), but then combine each list in a tuple:
import numpy as np
arr = np.random.rand(5, 5)
ind_x = [0, 0, 1, 3, 3]
ind_y = [0, 1, 3, 3, 4]
indices = (ind_x, ind_y)
arr[indices] = 0.0
print(arr)[[0. 0. 0.10249124 0.12661212 0.90427504]
[0.64015873 0.00303268 0.89185548 0. 0.25329674]
[0.94534295 0.1573885 0.05228583 0.22913484 0.56029745]
[0.86293179 0.47485238 0.69395909 0. 0. ]
[0.39098557 0.77951054 0.31083675 0.64076393 0.10685647]]In all of the above code snippets and examples we have seen that ndarrays can be created by lists as follows:
vals = [1, 2, 3, 4, 5]
arr = np.array(vals, dtype=int)
print(arr)[1 2 3 4 5]It is also possible to convert an ndarray back to a list:
vals = [1, 2, 3, 4, 5]
arr = np.array(vals, dtype=int)
vals2 = arr.tolist()
print(type(vals2))<class 'list'>Often we want to create an ndarray directly. We can create an empty array with a given shape and type:
arr = np.ndarray(shape=[5, 2])
print(arr)[[0. 0.42762076]
[0.61522461 0.44964016]
[0. 0. ]
[0.02798985 0.20205376]
[0. 0.63866539]]Note that the above array was filled with gibberish. These values are the numerical representation of whatever leftover data was stored in the memory that was assigned to hold arr. It is probably more useful to create an array of 1’s or 0’s, so numpy provides functions for that:
arr1 = np.ones(5, dtype=int)
arr2 = np.zeros(5, dtype=int)
print(arr1)
print(arr2)[1 1 1 1 1]
[0 0 0 0 0]Often we want to combine two 1D arrays into a 2D array, or vice versa. numpy uses the term “stack” to refer to joining arrays. This refers to the fact that arrays “stack” like blocks, either beside or on top of each other.
Splitting arrays into smaller ones is also fairly common. We have already seen that slice indexing can be used for this, such as:
arr = np.arange(16).reshape([4, 4])
a1 = arr[:2, :]
a2 = arr[2:, :]
print(a1)
print(a2)[[0 1 2 3]
[4 5 6 7]]
[[ 8 9 10 11]
[12 13 14 15]]However, it is often more convenient to use numpy's built-in functions. This makes it less likely to make mistakes for instance, and it’s also fewer lines of code:
arr = np.arange(16).reshape([4, 4])
1a1, a2 = np.vsplit(arr, 2)
print(a1)
print(a2)[[0 1 2 3]
[4 5 6 7]]
[[ 8 9 10 11]
[12 13 14 15]]